Protect your Environment from Malicious Pipeline Changes in Azure DevOps
I’ve recently been looking into ways to increase control and governance of continuous delivery practices when Azure DevOps Pipelines when using multi-stage YAML pipelines. My reason for investigating this area is that there are certain gaps in control when you’re just relying on “pipeline as code”.
In this post I’ll demonstrate how a number of different features in Azure and Azure DevOps can be combined to provide a very high level of control and governance over your environments. This is especially important when working in industries that require adherence to specific compliance standards and controls (e.g. health and finance).
Once you’ve read through this post you should have a good understanding of the different features in Azure DevOps that can be combined to meet whatever controls you need.
This post is not going to be an in-depth look at Azure DevOps security and permissions. That would take far too long and is not the goal of this post. However, it is important to remember that if you don’t set the appropriate permissions on the entities (branches, branch policies, service connections, variable groups, pipelines etc.) then users will be able to bypass the controls you set up. Therefor it is necessary to take security and permissions into account when you’re planning your controls.
In this post I’ll be focusing on Pipeline Approvals and how they can be enabled in different ways when combined with Environments, Service Connections, Variable Groups and Azure Key Vault.
The reason I decided to write this post is that it is not as straight to protect your secrets and environments when you’re implementing Pipeline as Code in Azure DevOps.
By way of example, consider you have a Git repository with a multi-stage Azure DevOps YAML pipeline defined in it:
This definition is triggered to only run on ‘main’ branch and never from a pull request. The pipeline also references Variable Groups and Service Connections, which should be considered protected resources, especially for the Production environment.
We also have an Azure DevOps Pipeline called Environment Continuous Delivery that uses the YAML file:
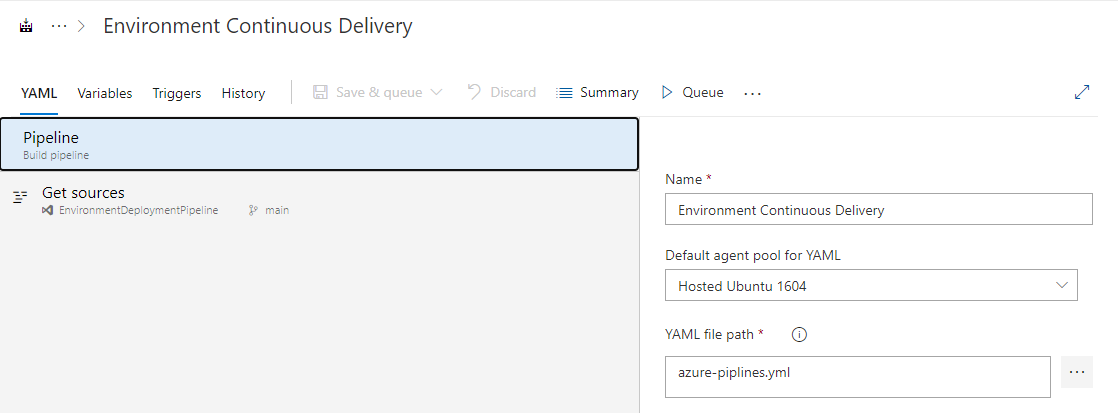
Azure DevOps Pipeline ‘Environment Continuous Delivery’ linked to azure-pipelines.yml
The triggers are not being overridden:
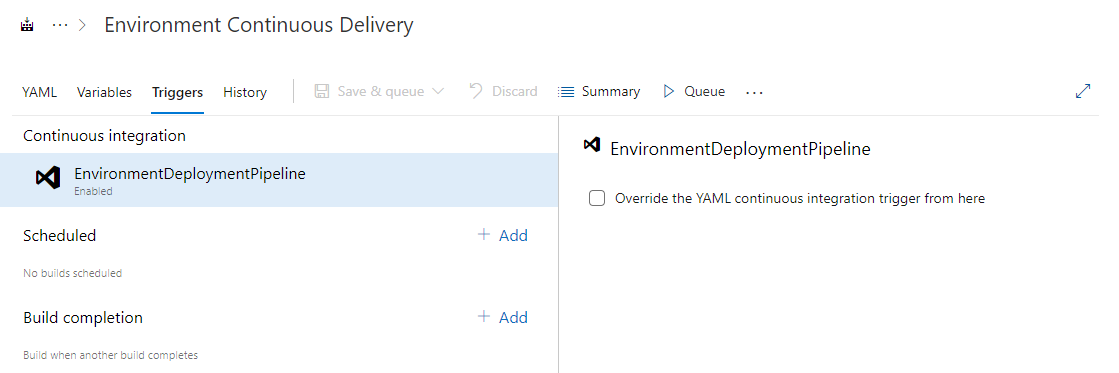
The pipeline triggers are not being overridden
The fact that the pipeline triggers are not being overridden means that the triggers defined in the YAML will always be used.
Finally, we have also locked main branch to prevent pushing code directly to it without an approved pull request. There is also a branch policy enabled that runs a simple CI build:

The branch policy and lock prevents direct commits/pushes to main branch.
However, the branch policy specifics aren’t actually important here.
So, what is the problem?
The problem is that any user may create a new branch off main and add malicious (or accidental) code to the azure-pipelines.yml. For example, if I create a new branch called malicious-change with azure-pipelines.yml changed to:
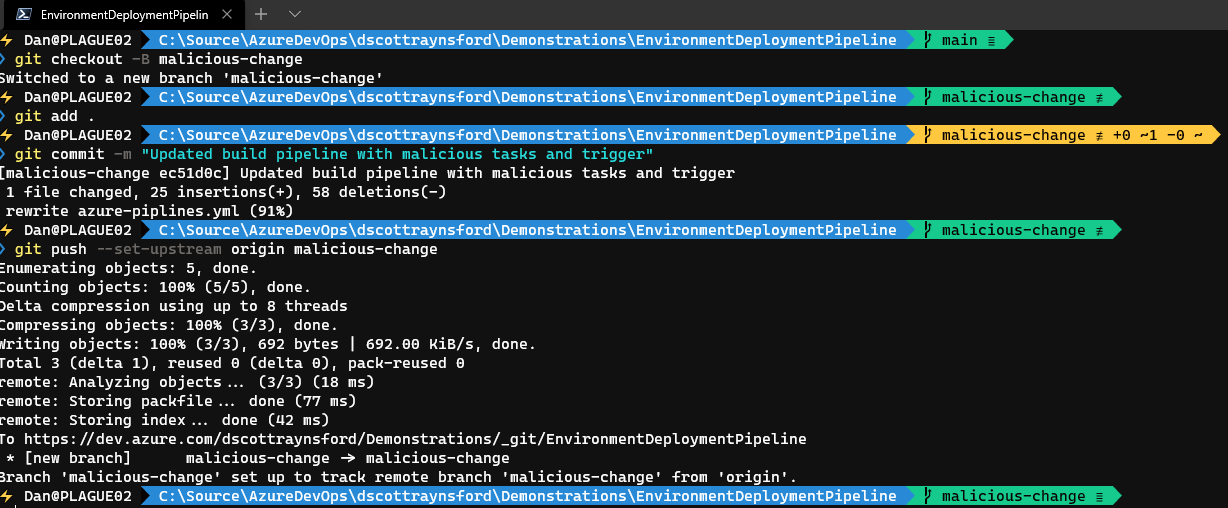
Create a new branch with malicious changes to pipeline definition.
If we then push that new malicious-change branch to Azure DevOps Git repo, then …
… the Azure DevOps pipeline Environment Continuous Delivery will automatically execute against this new branch with malicious/dangerous pipeline changes.

The pipeline runs and has access to all resources that this pipeline normally has.
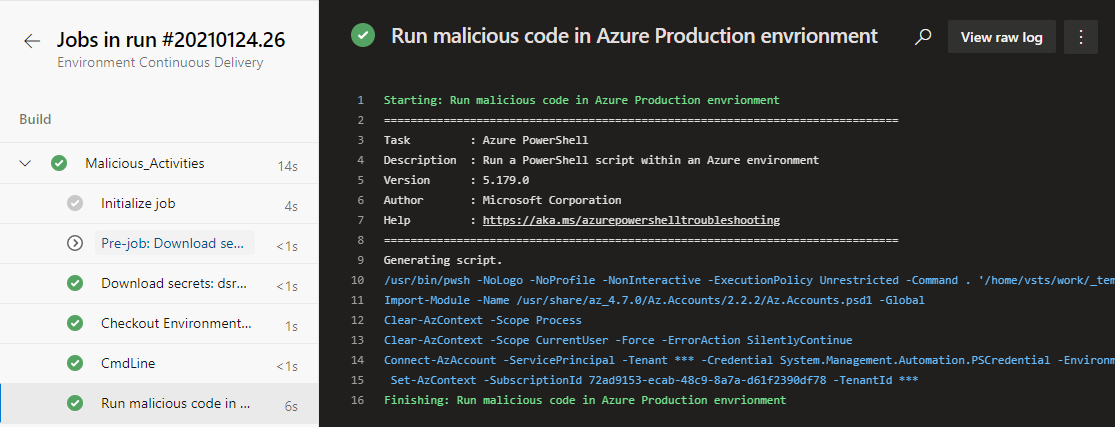
Pipeline is able to run commands with access to Azure Production resources.
Now that we know where the gaps are in our controls we can look for potential solutions.
There is a “quick and dirty” solution to this issue, but it does move us away from true “pipeline as code”. To implement this we simply need to override the triggers section in the pipeline so that it is no longer controlled by the azure-pipelines.yml:
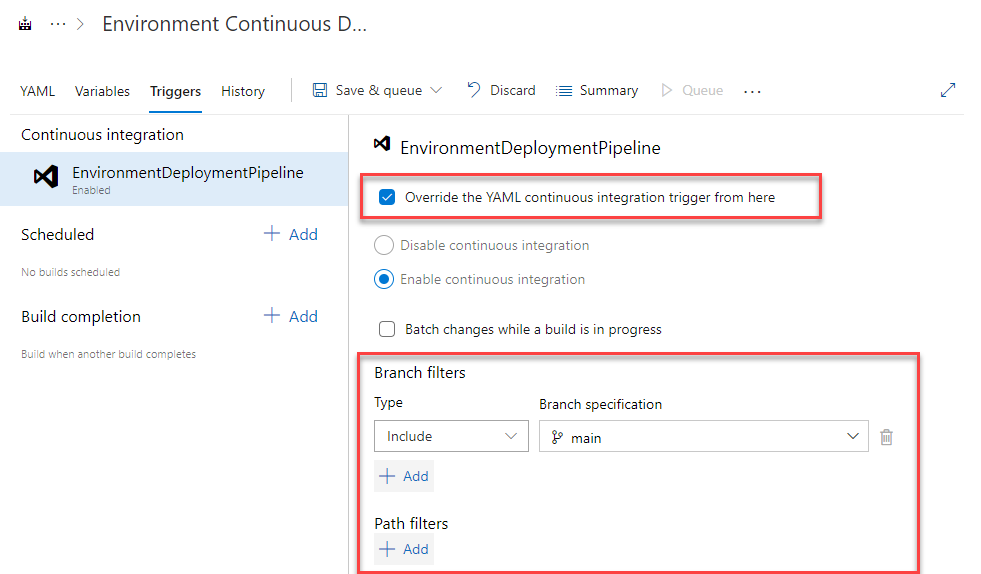
Overriding the triggers in the pipeline prevents the triggers section in azure-pipelines.yml from being used.
Although this solution is easy to implement it means that we’re not fully defining our pipelines with code. This means that someone with permissions to edit the pipeline would need to make any changes to branch or path filters, even when they are legitimate. Plus, there is a gap in the Azure DevOps UI which prevents us from overriding pull request triggers.
Alternatively, we could use Azure DevOps security to prevent creation of new branches by unapproved users but this will limit productivity and increases complexity, so I’m not even considering this a solution worth exploring.
So, let’s look at some better ways to protect our environments, secrets and service connections.
I’m going to increase the level of control and governance over the pipelines by implementing the following changes:
- Putting secrets into an Azure Key Vault and using a service connection with approvals & checks enabled on it. We’ll then create a variable group linked to the Key Vault.
- Adding approvals & checks to deployment service connections and allowing them to only be used within approved pipelines.
- Defining environments with approvals & checks and using them in your pipelines.
So, lets look at each of these in more detail.
The first task is to create an Azure Key Vault and add all the secrets that are used in a pipeline into an Azure Key Vault. In my case, I added SQL server login details as two secrets:
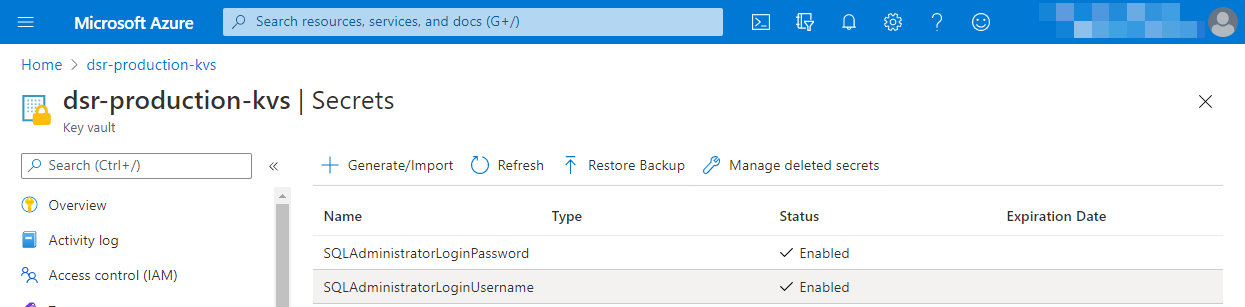
My production Azure Key Vault
In my case, I have two environments, QA and PRODUCTION. So, I created a resource group and a Key Vault for each. This is so that I can implement different levels of controls over QA to PRODUCTION.
Note: As part of this process you should also use other techniques such as governance with Azure Policy, sending logs to Azure Log Analytics to harden and protect your Key Vaults. But this is beyond the scope of this post.
Next, I need to create a Service Connection to Azure Resource Manager to the resource group I created the Key Vault in:
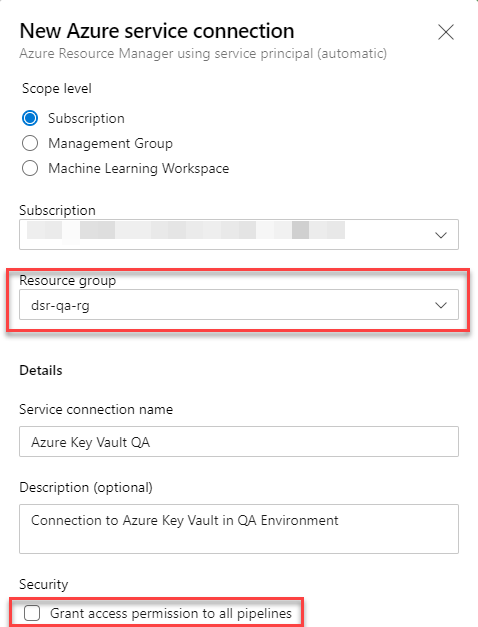
Take note that I limited the connection to the Resource Group and didn’t grant permission to all pipelines.
I then need to edit the security for the Service Connection to grant access to it from specific pipelines:
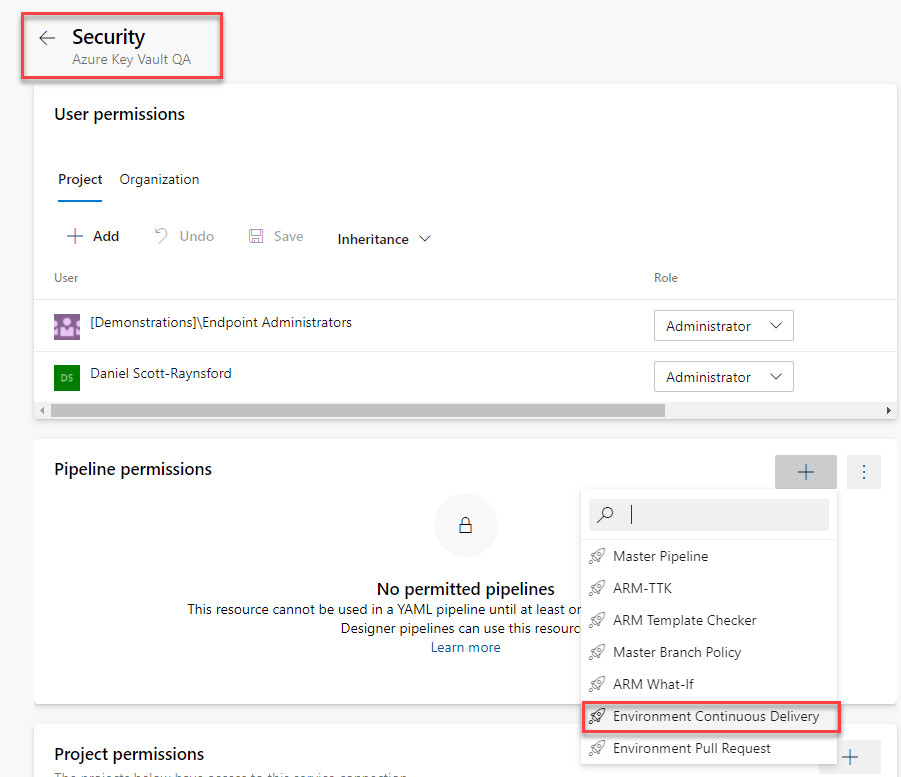
What we then need to do is add approvals and checks to the service connection. This will cause these checks to be run any time a pipeline tries to use the service connection:

Adding Approvals and checks to a Service Connection.
There is one approval type (getting approval from a user or group) and several checks that can be enabled:
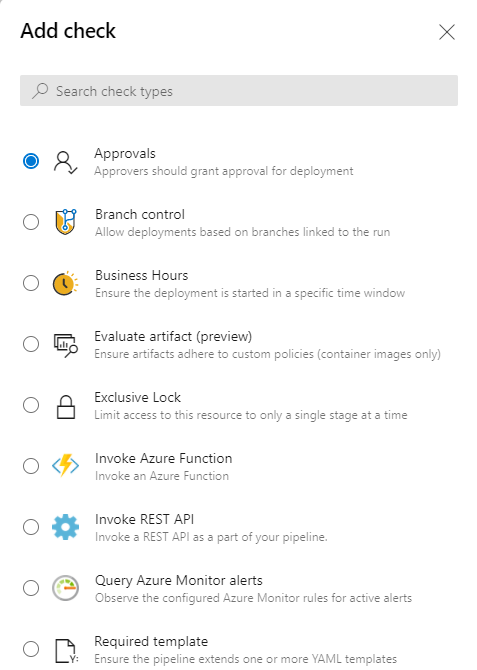
Adding approvals and checks on a Service Connection.
Depending on the level of control you’d like to implement on each environment, you might configure these checks differently. In my case, for QA I only used a branch control to only allow the connection to run against main branch.

The Azure Key Vault QA service connection can only be accessed when run within main branch.
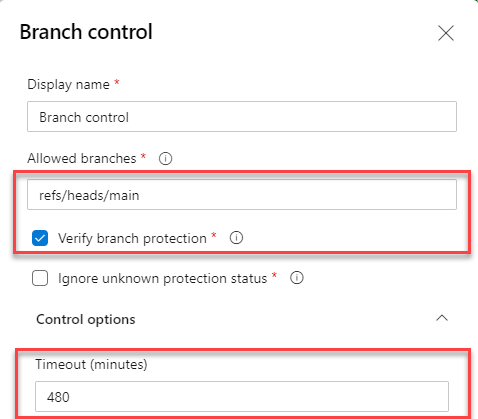
Take care to format the Allowed branches using the full ref path.
By enabling verify branch protection it will ensure the service connection is only available if the branch protection for the branch is enabled. It should be ticked for QA and PRODUCTION.
For, PRODUCTION, I enabled both a branch control and Approvals from a security group:
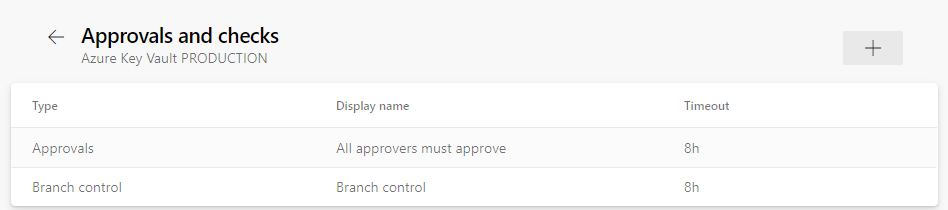
The Azure Key Vault QA service connection can only be accessed when run within main branch and also requires approval from a group.
For the Approval gate I had a group defined called Production Environment Approvers. I could have used an Active Directory group here instead. Using a group is recommended rather than specifying individual users because only a single member of each group needs to approve. See this document for more information on setting approvers.
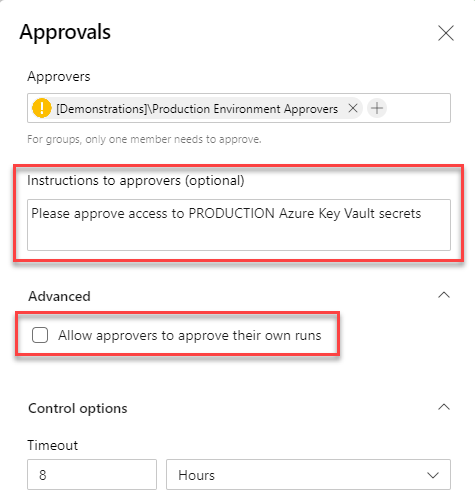
To enforce separation of duties, make sure approvers can not approve their own runs.
The final task is to create the Variable Groups linked to the Azure Key Vault, using our service connections:

Variable groups linked to Azure Key Vaults.
To keep this post short(er), I won’t describe the exact steps here. You can get more detail on the exact process on this page.
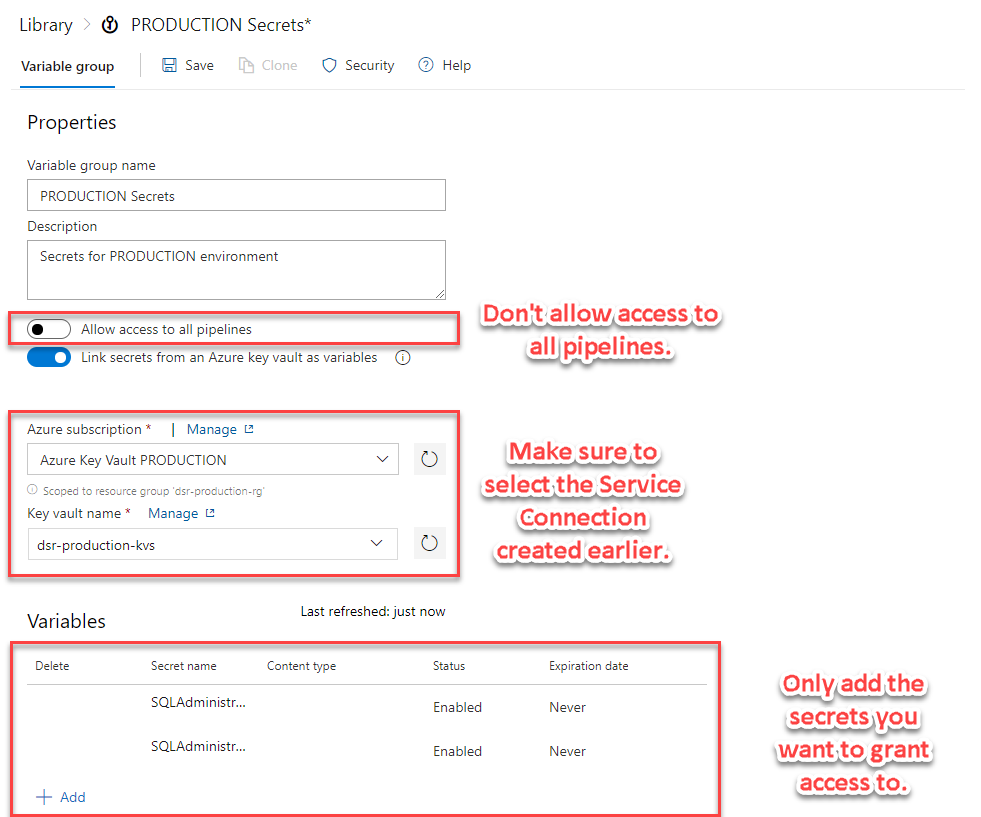
It is important to not allow access from all pipelines.
Because we unticked the allow access to all pipelines box, it will mean the owner (or someone with enough permissions) will be asked to approve the use of the variable group and Key Vault service connection the first time the pipeline is run:
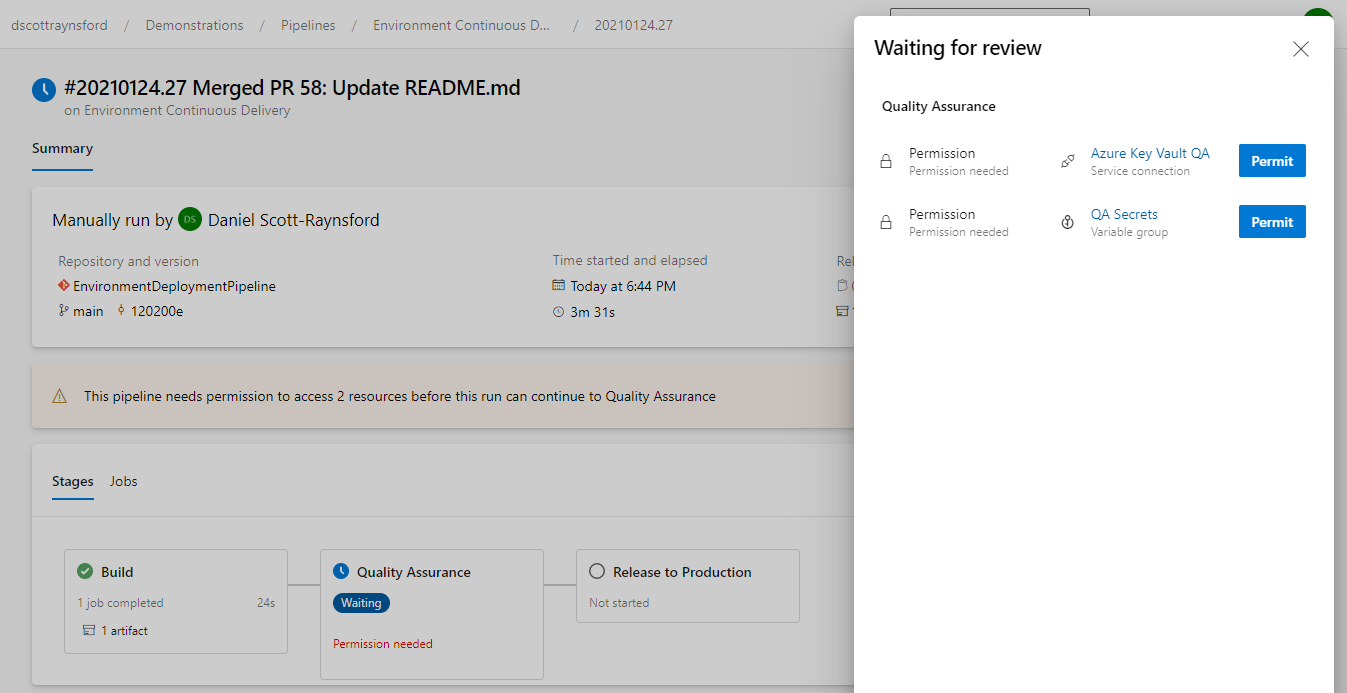
Both the Azure Key Vault QA service connection and QA Secrets variable group need to be granted permission on the first run.
Subsequent runs of this pipeline won’t require permission.
The Variable Group gates and approvals only work if linking it to an Azure Key Vault - which is another good reason to use them.
Now we have a much higher level of governance over our pipeline secrets, so let’s move on to the next improvement we can make.
The next method we’ll implement is to add approvals & checks to our PRODUCTION (and QA) service connections. This is just the same as I did in the previous section for the Azure Key Vault service connections:

PRODUCTION Service Connection approvals and checks.
We could implement similar approvals & checks to any service connection, not just to Azure. For example, we might do this for connections to Kubernetes clusters, Service Fabric clusters, SSH or Docker hosts, or any other service.
Next, we also want to limit the service connection to only be accessible to specific pipelines, just as we did for the Key Vault connections.

Grant permissions to pipelines we want to allow this Service Connection to be used in.
We now have individual controls over secrets and resources used within our continuous delivery pipelines.
If we have a pipeline with a stage that requires access to multiple service connections or environments protected with approvals we don’t need to approve them all individually:
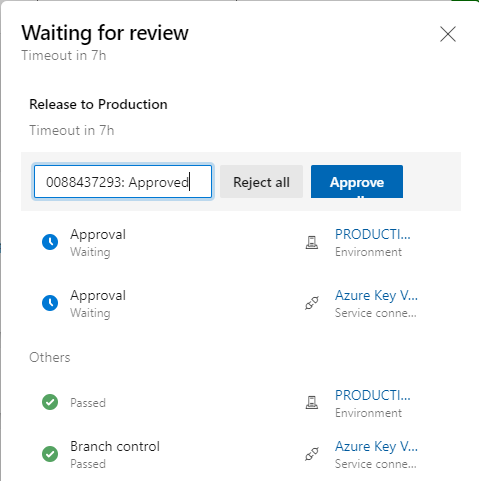
We can approve all gates together or individually.
However, you can only approve when you’re a member of the Approvers that were specified in the Approval gate.
The final improvement is to make use of the Azure DevOps Environments feature. This allows us to define an environment to target when using a deployment job of an Azure DevOps Multi-stage YAML pipeline. With the environment defined, we can assign approvals & checks to that, just like we did with the Service Connections and limit permissions to the environment to specific pipelines.
Note: An environment can be used to define deployment targets for specific resources types such as Kubernetes namespaces and Virtual Machines. However, these are not required and you can still get a good deal of value from using environments without defining resources. See this blog post for more details.
In my case, I defined two environments, one for QA and one for PRODUCTION:

PRODUCTION and QA environments do not need to contain resources, but can still add value.
Just like before, I grant permissions to the environment for specific pipelines:
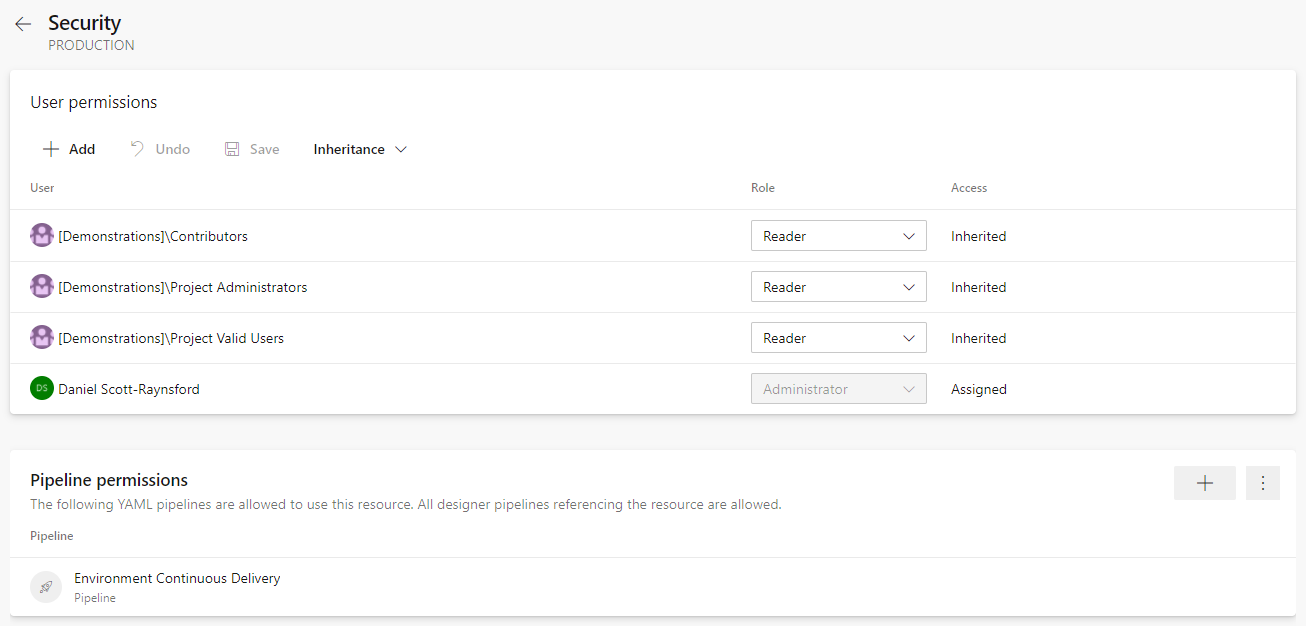
Limit environments to be used by specific pipelines.
I also define approvals & checks for the PRODUCTION environment just like before, but I also added an Exclusive Lock check that will prevent more than one pipeline deploying to the PRODUCTION environment at the same time. This isn’t strictly a governance control, but will reduce the risk of conflicting deployments occurring.

Prevent multiple deployments to this environment at the same time with the Exclusive Lock.
Finally, we need to update the azure-pipeline.yml to make use of the environment and the variable group:
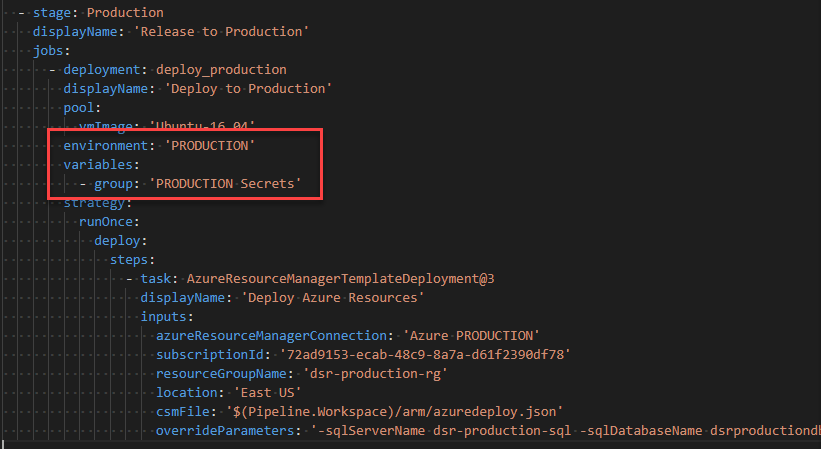
Setting the environment to PRODUCTION in a deployment job.
We can now get now also get a single view of all deployments to an environment:
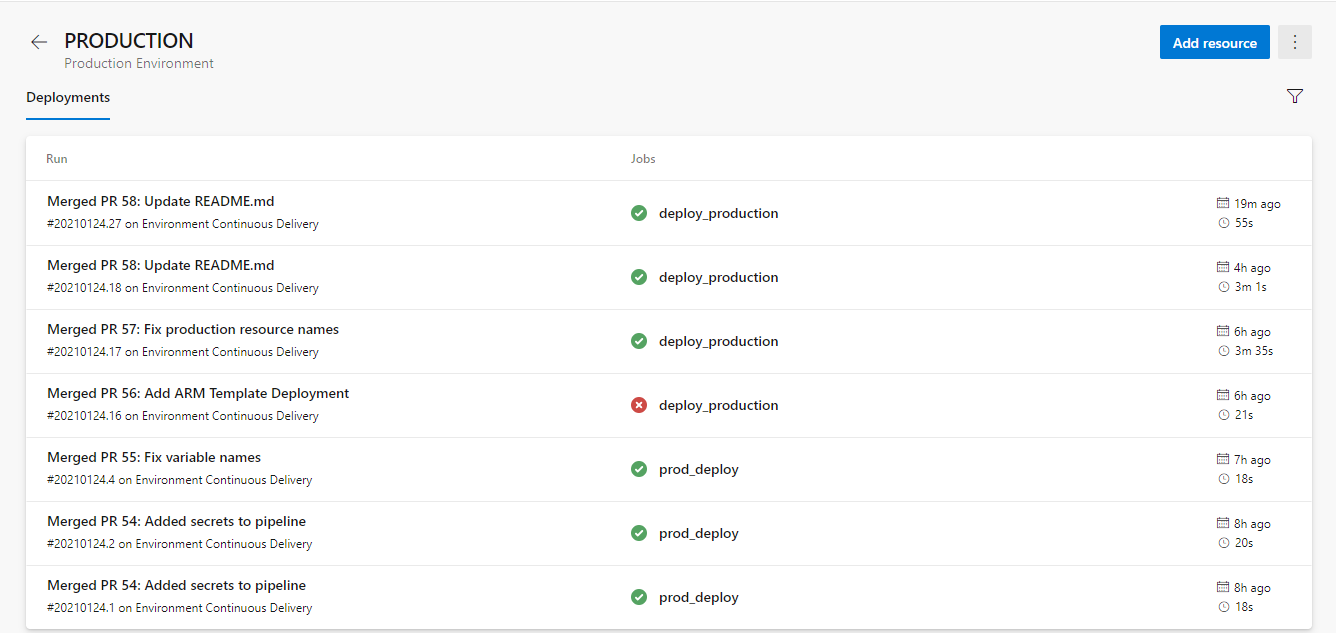
All environment deployments to PRODUCTION.
Because environments aren’t defined across projects, this is another reason to limit the number of Azure DevOps projects you’re creating. See my previous blog post on 12 Things you Should Know when Implementing Azure DevOps in your Organization.
Now that we’ve completed all these additional checks and approvals, let’s see what happens when we attempt to get some malicious changes to run inside our Environment Deployment Pipeline:
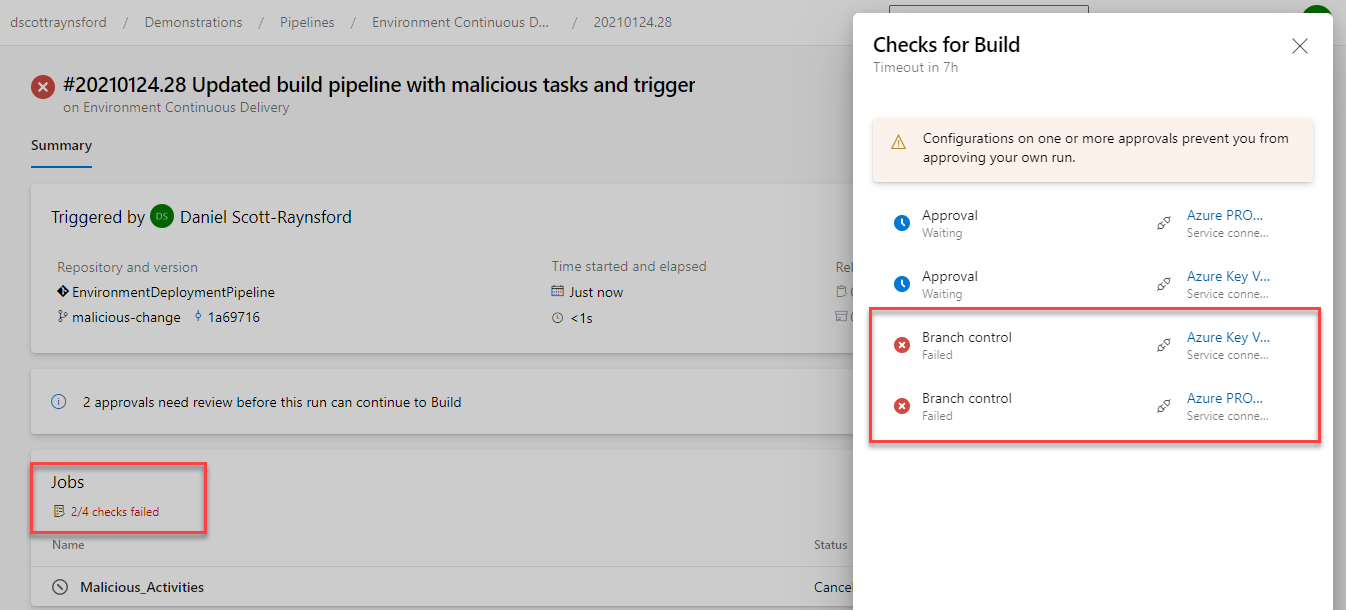
After creating a new branch called Malicious_Activites off main with adjustments to azure-pipelines.yml the build fails.
As we can see from the screenshot above, the following things have happened:
- The Environment Continuous Delivery pipeline was triggered automatically by our commit to the new Malicious_Activities branch. This was expected and is the same as before.
- This time all our Branch control checks on the Service Connections that were maliciously trying to be accessed have caused the build to fail because this is not main branch.
- The Approvals to access the service connections have been requested still, but because I created the commit that triggered this, I can’t approve them. This results in implementation of separation of duties control.
For a member of the Production Environment Approvers group it looks like this:
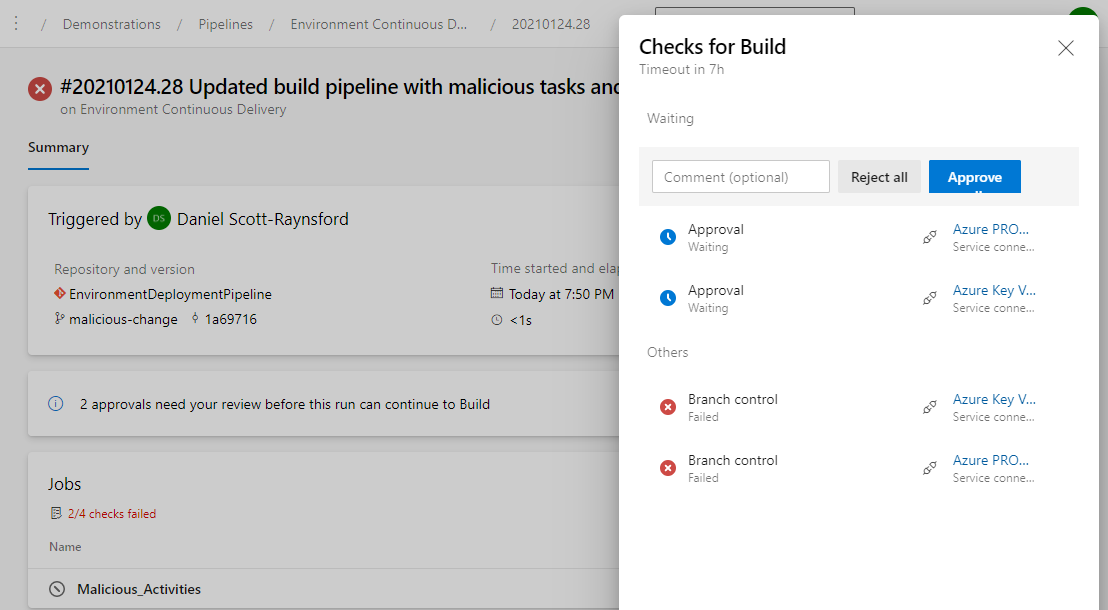
Approval allowed, even though the job has failed.
Even after the approving the job checks will still fail and the job won’t proceed. So, this means our PRODUCTION environment has been protected.
If we run the pipeline against main branch (either manually or via a commit via a Pull Request) then we will get the standard approvals:
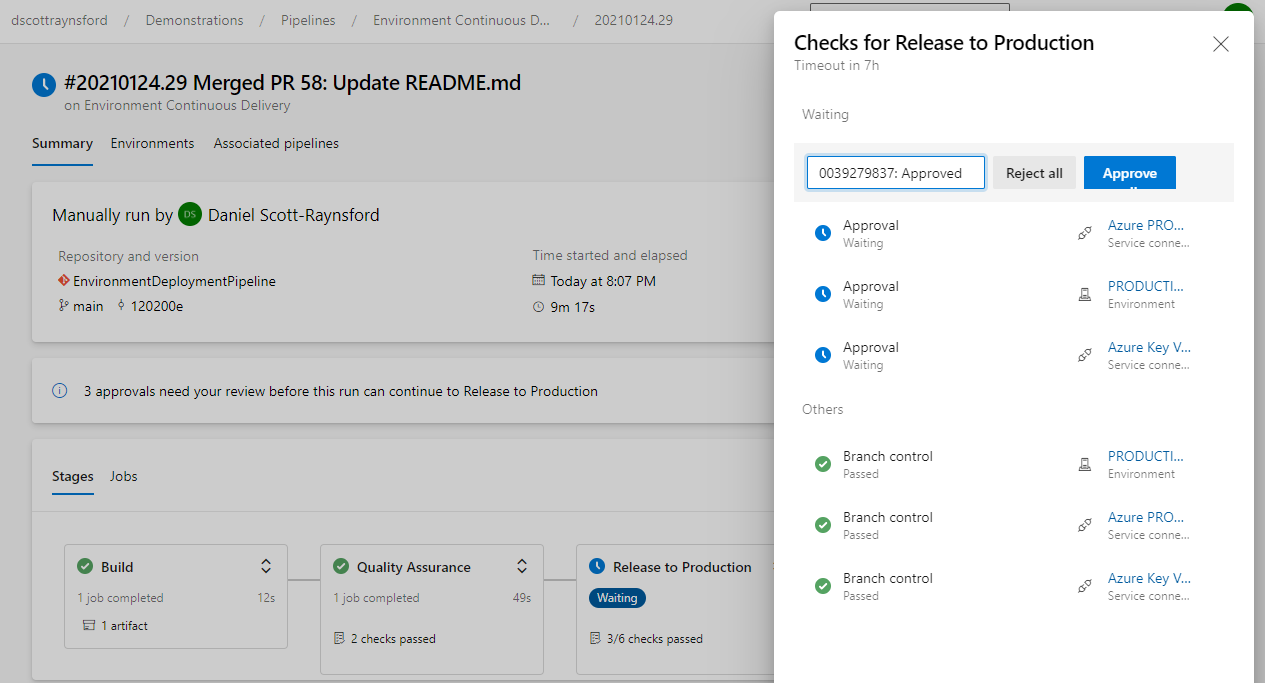
QA checks passed automatically, and PRODUCTION Branch controls have passed. PRODUCTION approval is waiting.
By default approval notifications will be e-mailed to anyone who is in an Approval list. You can disable this by configuring your Notifications:

Enable/Disable Run stage waiting for approval notifications.
You can also choose to have notifications delivered to you in Microsoft Teams, if you use it. This is the best way to experience these features and you’re less likely to miss an important approval.
It is important to remember that all of these controls and methods are optional. If you don’t need this level of control and governance over your environments then you shouldn’t add the complexity that goes with it. That said, it is always good to know what you can do with the tools, even if you don’t need to use it.
I hope you found this (long, but hopefully not too long) post useful.